Deep Data Analytics
Generating realistic biomedical data using Deep Learning techniques:
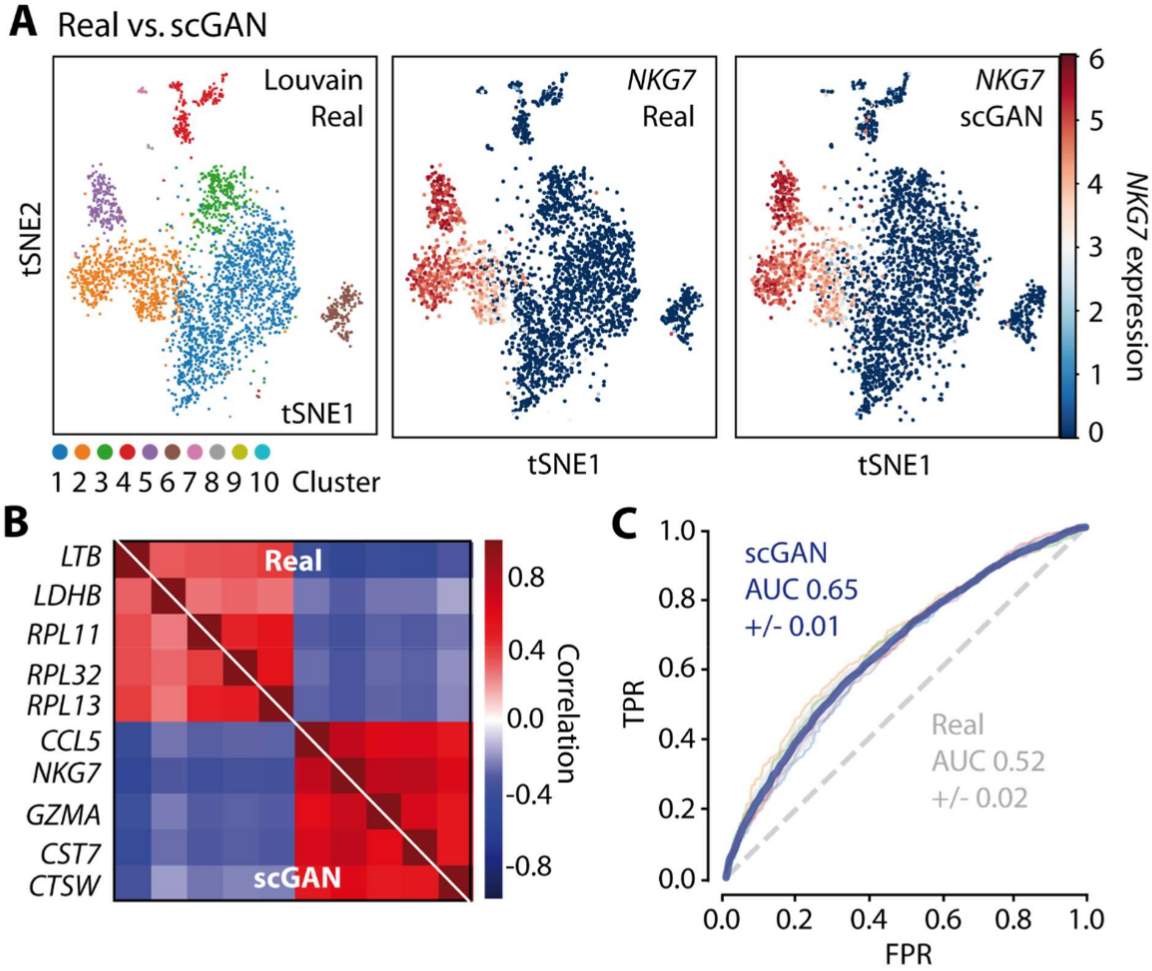
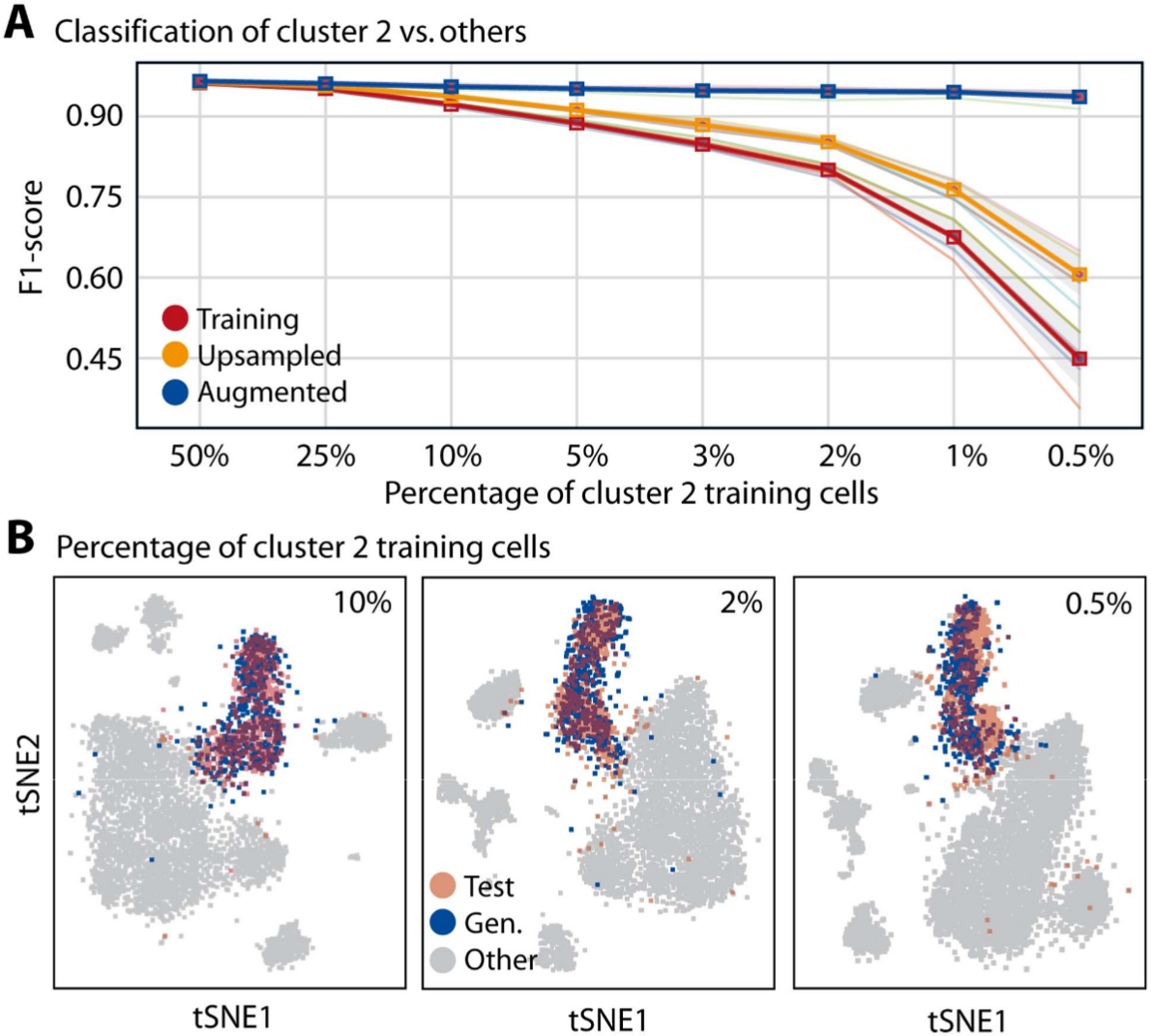
conditional Generative Adversarial Networks (cGANs) are used to generate in silico single-cell
expression profiles that cannot be distinguished from real profiles. GANs learn complex gene-gene
dependencies from multi cell type complex samples and use this information to generate realistic
cells of defined type. The technology can be used for any data domain where a low amount of
observations is available, but more samples are desirable – to save animal lives and money and
to increase reproducibility of results.